Fonte: http://www.devmedia.com.br/unicode-conceitos-basicos/25169
Unicode: conceitos básicos
1. Introdução
Unicode é um padrão adotado mundialmente que possibilita com que todos os caracteres de todas as linguagens escritas utilizadas no planeta possam ser representados em computadores. A “missão” do Unicode é apresentada de forma clara no web site do Unicode Consortium (entidade responsável pela sua gestão):
Unicode fornece um número único para cada caractere, não importa a plataforma,
não importa o programa,
não importa a linguagem.
não importa o programa,
não importa a linguagem.
O padrão Unicode é capaz de representar não somente as letras utilizadas pelas linguagens mais “familiares” para nós ocidentais, como Inglês, Espanhol, Francês e o nosso Português, mas também letras e símbolos utilizados em qualquer outra linguagem: Russo, Japonês, Chinês, Hebreu, etc. Além disso, inclui símbolos de pontuação, símbolos técnicos e outros caracteres que podem ser utilizados em texto escrito.
2. Como o Unicode Trabalha?
No padrão Unicode, cada diferente letra ou símbolo de cada alfabeto utilizado no mundo é mapeado para um diferente code point. O code point é um código no formato U + número em hexadecimal. O exemplo abaixo mostra os códigos das letras que compõem a palavra “BRASIL” (em maiúsculo).
B - U+0042
R - U+0052
A - U+0041
S - U+0053
I - U+0049
L - U+004C
R - U+0052
A - U+0041
S - U+0053
I - U+0049
L - U+004C
É muito importante mencionar que as letras maiúsculas possuem code points diferentes das letras minúsculas. Por exemplo: o code point da letra “A” é U+0041, enquanto o da letra “a” é U+0061, o code point de “Ç” é U+00C7 e o de “ç” é U+00E7 (e por aí vai). Outra observação importante é que os primeiros 127 code points (até U+007F) são compatíveis com os códigos utilizados na antiga tabela ASCII (basicamente são os códigos associados aos números, letras maiúsculas e minúsculas sem acento e símbolos de pontuação mais comuns).
O aplicativo Mapa de caracteres (charmap) do Windows pode ser utilizado para consulta à tabela Unicode. Para acessá-lo, basta ir para o Prompt de Comando e digitar charmap. Na Figura 1, o Mapa de caracteres informa o code point associado à letra grega alfa.
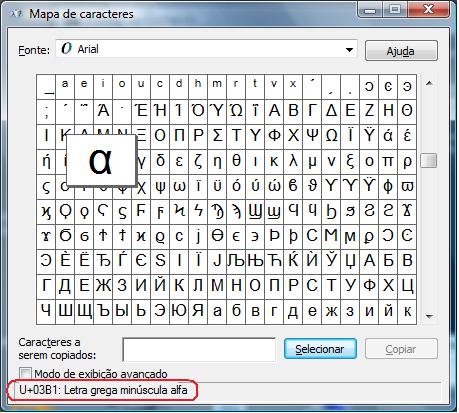
Figura 1: Mapa de Caracteres
3. Encodings
Do que foi apresentado na seção anterior, podemos entender que o Unicode nada mais é do que uma enorme tabela que associa um número único (code point) para cada diferente letra ou símbolo dos alfabetos de todo o mundo. Mas como esses code points podem ser armazenados em um arquivo texto ou na memória do computador? É aí que entram em cena os encodings.
Um encoding é uma técnica que define regras para armazenar os code points dos caracteres que compõem as strings na memória do computador. Existem vários deles: UTF-8, ISO-8859-1 (apelidado de Latin-1), UCS-2, Windows-1252, etc. Cada encoding utiliza uma técnica distinta para lidar com os códigos Unicode.
O encoding UTF-8, por exemplo, é capaz de representar qualquer caractere Unicode. Para conseguir isso, utiliza uma técnica que onde uma quantidade de 1 a 6 bytes pode ser utilizada para representar cada caractere. Ou seja, o UTF-8 não trabalha com uma representação em tamanho fixo. Os code points de 0 a 127 são armazenados com 1 byte. Porém, os demais podem ser armazenados em memória com tamanho de 2 a 6 bytes.
O UTF-8 é completo (armazena qualquer caractere Unicode) e usa uma técnica de armazenamento que pode ser considerada “sofisticada”. Outros encodings, como ISSO-8859-1 e Windows-1252 são menos completos do que o UTF-8, e preferem trabalhar apenas com um subconjunto da tabela Unicode (ex: apenas com caracteres das linguagens ocidentais). Em compensação, podem fazer uso de técnicas de armazenamento mais simples que, além disso, conseguem representar strings gastando um número menor de bytes.
Agora você já sabe o que significa Unicode e sabe diferenciar Unicode de encoding! Este é, sem dúvida, um passo importante para começar a “perder o medo” de encarar esse tema (que reconheço é bem chato de se estudar!). Para aprender mais sobre o assunto, recomendo a leitura do simpático tutorial disponibilizado emhttp://www.joelonsoftware.com/articles/Unicode.html. Boa sorte e até a próxima!
Leia mais em: Unicode: conceitos básicos http://www.devmedia.com.br/unicode-conceitos-basicos/25169#ixzz3Jzh97hQQ